谷歌出品的 CSS 教程科技爱好者周刊(第 160 期):中年码农的困境 - 阮一峰的网络日志
来源:科技爱好者周刊(第 160 期):中年码农的困境 - 阮一峰的网络日志
摘录内容
1、CSS 学习教程

,内容很丰富全面,一共有 24 课。(@wxyudl 投稿)
来源:科技爱好者周刊(第 160 期):中年码农的困境 - 阮一峰的网络日志
1、CSS 学习教程
,内容很丰富全面,一共有 24 课。(@wxyudl 投稿)
Save From : 科技爱好者周刊(第 207 期):汽车行业的顶峰可能过去了 - 阮一峰的网络日志
1879年,一个美国人问道:”为什么所有这些新的经济发展和工业化技术,都没有消除贫困和压迫?” 那个人就是亨利·乔治,后来他写了一本名为《进步与贫困》的书。
-- 《<进步与贫困>书评》
来源:科技爱好者周刊(第 208 期):晋升制度的问题 - 阮一峰的网络日志

一个浏览器插件,只要访问 Chrome 网上商店的某个插件主页,就会显示插件源码的地址。它还有在线版。
Save From : 通过VNC访问docker容器的图形界面_spylyt的博客-CSDN博客_docker vnc
From Docker Index
1 | docker pull dorowu/ubuntu-desktop-lxde-vnc |
Build yourself
1 | git clone https://github.com/fcwu/docker-ubuntu-vnc-desktop.gitdocker build --rm -t dorowu/ubuntu-desktop-lxde-vnc docker-ubuntu-vnc-desktop |
Run
1 | docker run -it --rm -p 8080:80 dorowu/ubuntu-desktop-lxde-vnc |
邮件服务器安全 SPF、DKIM、DMARC_吉吉教主的博客 - CSDN 博客_dkim spf
SPF 是指 Sender Policy Framework,是为了防范垃圾邮件而提出来的一种 DNS 记录类型,SPF 是一种 TXT 类型的记录。
SPF 记录的本质,是向_收件人_宣告:本域名的邮件从清单上所列IP发出的都是合法邮件。
下面例子中,tencent.com 宣告:spf.mail.tencent.com 、spf.mail.qq.com 是合法的,其他不合法。
DKIM 技术通过在每封电子邮件上增加加密标志,收件服务通过非对称加密算法解密并比较加密的 hash,判断邮件伪造。
DKIM 的基本工作原理是基于密钥认证方式,他会产生 1 组钥匙,公钥 (public key) 和私钥(private key)。公钥将发布在 DNS 中,私钥会存放在寄信服务器中。发件时,发送方会在电子邮件的标头插入DKIM-Signature及电子签名信息,详见下方截图。
收件人邮件服务器收到邮件后,会通过 DNS 获得 DKIM 公钥,利用公钥解密邮件头中的 DKIM 信息中的哈希值,收件服务器再计算收到邮件的哈希值,两个值进行比较,如果一致则证明邮件合法,则传递邮件。如果验证为不合法,则判定为垃圾邮件。 由于数字签名是无法仿造的,因此这项技术对于垃圾邮件效果极好。
以下是一个 DKIM 签名的例子。其中 b 字段是利用私钥对邮件头、邮件体做的数据签名;bh 是 body 的 hash。

DNS 获取的公钥信息,其中 p 字段是公钥。
DMARC(Domain-based Message Authentication, Reporting and Conformance)的目的是给电子邮件域名所有者保护他们的域名的能力,SPF 和 DKIM 缺少反馈机制, 这两个协议未定义如何处理 “仿冒邮件”。DMARC 的主要用途在于设置 “处理策略”, 当收件服务接收到来自某个域未通过身份验证的邮件时,应执行的 dmarc 规定的处理机制。
下图例子中,域名拥有者通过 DNS 发布 DMARC 策略,当收件者收到 “仿冒邮件时” 执行以下策略:
p:none 不采取对域名的标记。
rua:发送综合反馈的邮件地址。
ruf:发送消息详细故障信息的邮件地址。
测试方法:https://dmarcian.com/dmarc-inspector/?domain=example.com#
新上特级美早,果径 36mm-38mm
超 4J 规格,只挑凌晨 2 点采摘的最优果品
仅需 298 元 / 2.5kg!
生存群初建,原价 365 / 年,现价仅需 265 元
机会难得,点此立刻加入: 报名地址
1、底层人的幻想
又到了高考日。路上到处是「为高考护航」的严阵以待,满满的仪式感。
温州大学退休教师陈云舟又发旧文怀念他四十年前的高考。陈老师当初只有小学学历。所幸他有一个好家庭:父亲支持他高考,有一个已经考上杭州大学英语系的妹妹可以教他英文,有一个略通日语的母亲做他日语启蒙老师,一切从零开始。
陈云舟还遇到贵人:勤奋外语学校的叶显崇老师带他一程,一代名师陈惠生让他日语突飞猛进,终于考上杭州大学(浙大西溪校区)日语系,毕业后成为大学教师。
相对于陈云舟这样被文革耽误,靠着小学学历四处求学、发愤图强的那几届高考生,今天孩子们读书条件真是太好了,好得不可思议。
1977 年,中国恢复高考,录取了 27 万大学生。对于 1977 年到 1981 的那几届考生而言,「高考改变命运」绝对是很多人的切身体验。
2022 年,中国大学毕业 1076 万人。大学生人数是以前的 40 倍。很多人依然怀着「高考改变命运」的念头,不惜代价去参加高考——甚至可以说前面十几年苦读就是为了高考。
与陈老师感慨「高考改变命运」不同,同样是温州人,身为商人的慕容逸却根本不在乎孩子的高考,甚至把上初二的女儿拉到公司实习,让她从头到尾做外贸订单。慕容逸如此教育女儿:
1)知识改变命运,或高考改变命运,是寒门子弟的观念。咱家不是寒门;
2)外贸是咱家的家学。别人在大学外贸系读四年,在学校学到的东西也不如你在家实习一个月;
3)老爸也没上过大学,无论英语还是理论力学,都靠自学。
什么叫底气?这就是。
如果你在二十多年前考上大学,可以证明你至少在学业上是属于当年最优秀的几十万人。但是你若是在高校扩招后考上大学,很抱歉,你不过是今年 1076 万毕业生之一。
其中 800 万左右,会成为失业者。
慕容逸那种外贸世家,在他女儿初中时已经熟悉外贸生意的全套流程,非常清楚每个环节需要什么知识点。女儿无论读不读大学都无所谓,因为初二的她,英文能力已经很好,足够应付外贸生意。未来需要什么知识技能,她也已经一清二楚。
但是大多数底层出身的人正在面临英语还不如体育占分高的困惑,被高考指挥棒折腾得晕头转向。他们没有自己的规划,或者说唯一的规划就是高考拿个好分数。
慕容小姐这种「商三代」从小用英语实习外贸的时候,指望「高考改变命运」的人还在一次又一次刷题——这种刷题除了应试,并没有别的好处。对于真正的教育,刷题是人生极大的浪费。
大多数的底层出身的中国人,到了高考时还没找到自己的志趣和方向,不知道自己将来要做什么。
甚至有些人混到大学毕业依然不知道自己要做什么,无论是人生规划、技能准备,依然茫然。
那些稍有主见的,或许给自己做了很好的人生规划。很遗憾。毕业后发现根本连那个行业的门都进不去。因为他想象中等他的那些位置,早已经被占据——有些人是因为爹妈比你爹妈更有能力,有些人是因为自身条件远比你好,有些人是因为不缺钱,可以接受很低工资从零做起混经历。还有人太能吃苦,接受 996 还可以忍受各种委屈。
大多数希望靠高考改变命运的人,最终都变成失业者。
2、内卷不过是一种借口
内卷是最近流行的借口,主要用途是让 loser 为自己的失败找到合理解释。
在一个传统的分工社会,渔樵耕读,大家都做自己的事,哪里有什么内卷?
万物都有自己的生态位。鸟在天上飞,鱼在水里游,蚯蚓在土里钻,这是他们的空间生态位。
牛羊吃青草,野猪拱地瓜,狮子围猎,蚯蚓吃腐殖土,蛆虫吃腐肉,草履虫吃小球藻,小球藻靠光合作用,它们各有自己的生存之道。
如果所有人都觉得自己就是牛羊,都去抢一片青草地,那就是内卷。
内卷的背后,是价值观的单一。 人没有独立思想,无法获得「自足」,生活在「主流价值观」的评论中,就会变得标准化。
说白了,所谓内卷就是二个意思:1、你没有特长;2、你没有独立思想。
每个行业最优秀的人,从来不在乎内卷。无论如何内卷,他们永远站在最顶端。任何一个行业的头部都是屈指可数的。
即便他们做内卷最厉害的职业,比如公众号写手(这大概是竞争最激烈的行业,因为门槛低,人人可以做),你会发现高手即便从一个新号开始,就能在很短的时间出一批十万加的文章。而其余几百万作者,99% 一辈子也写不出一篇十万加的原创文章。
六神磊磊那种人,随时可以脱颖而出。这就是头部实力。
对于没有头部实力的人,适合做的就是「逃离竞争」。 比如你在镇上开一家理发店,即便全中国有一百万理发师,你的邻居也还是会找你理发,西班牙和印度的理发师更不可能抢走你的生意。
或者换一种活法。你在甘肃天水种樱桃、种苹果,别人的高考学历内卷又和你有什么关系?
3、上了大学,人就废了
「读书读傻了」,这是我年轻时代经常听到的一句话。我也被人嘲笑过好几次。
这是事实,而且非常普遍。人若是不识字,别人要把你变傻是很难的。一旦识字,就很容易变傻。因为你会相信书上白纸黑字写的那些道理都是真的。
书上那些数理化知识,确实很靠谱。但是关于社会、三观方面的,经常和现实南辕北辙。
学校的目的是「教化」,而不是「教育」。 要把你变成国家和社会需要的人,而不是为了帮助你成为自己希望成为的那种人。
犹太人有一句谚语:「真正的教育在饭桌上」。
无论是西方,还是东方,教育差距最大的部分不在学校,而在饭桌上。家学,才是最重要的。让你输在起跑线上的不是学区房,而是你父母的观念。
同学和你读一样的书,做一样的作业,就以为他们受到和你一样的教育,那就是犯傻。
大学还有一种办法把人搞废:让不够聪明的人考上大学,还让他毕业。
当孩子们拿到毕业文凭的时候,会产生这样的幻觉:1、自己是个有知识的人了;2、自己是个有身份的人了。
大学课本上的知识学生真懂了吗?其实很多课程门槛都是很高的,学生真的是靠老师划重混过去的。
当年中国科技大学创办不久,招了一群全国最顶尖学生,一次考试时钱学森出的一道计算卫星轨迹的考题:「从地球上发射一枚火箭,绕过太阳再返回地球上来,请列出方程式求解」。这是美国学校里的常规习题,钱学森只是照搬美国的题目。
这真算不上难题。三百年前的第谷、伽利略时代的人都做过。牛顿以后,这更不是难题。但是学生做了一整天,95%不合格。
于是钱学森决定:这一届学生不行,学制延长一年毕业。
按照钱学森的标准,可能中国今年 1076 万毕业生至少有 1000 万是不合格的。
有位心理学教授跟我聊天,提到一件事:学术界很多人心理学博士毕业后,忽然觉得自己好像从未学过心理学。本科时期课本上那些认为理所当然的概念和理论,仔细辨析起来都是「有待商榷」或「千疮百孔」。
为何出现这种情况?因为学生们在本科阶段只是记住标准答案和课本上的理论,并没有思考和质疑的能力。如果没有做博士论文时候的几年深入思考,就以为自己真懂了。
这就是大学教育的问题:越是不会思考、没学懂的人,越容易以为自己有知识。大学扩招越多,这种人就越多。
一旦到了社会上,就会陷入困境:真正企业需要解决的问题,他解决不了。那些找得到的工作,在他看来是太简单,简直羞辱他的知识和大学文凭。即便勉强去做,也不会安心做。
「怀才不遇」的心结会伴随他多年。但是真正的才华他又没有,他只有一张文凭而已。
4、出国留学,
也会变成另一个笑话
出国留学,是很多人认为改变命运的另一条渠道。随着对外交流的增多,一些国外学校不仅承认 A level, IB,也承认中国的高考成绩。
每年高考之后,很多没考上 985 或 211 的有钱人的孩子会在几个月后出国留学。
在中国进不了名校的人,通常在国外更进不了名校。初等教育没有形成批判性思维能力的人,长大后再出国留学也很难改变。
小留学生们大多数出生于「得到足够好处」的那些富二代和 x 二代。出国前家里就给准备了四年的学费和生活费。更有富二代出国就配置豪车。当他们面对那些学费都要按月分期付款的美国穷同学,或许会升起一股「还是祖国好」的自豪感。
但是,他们很快发现自己的学业未必比美国学生好(虽然很多人曾以为美国学生数学差到一塌糊涂),毕业后在海外的求职竞争力更是远不如他们的外国穷同学,甚至在泡妞方面的优势还不如贫民窟长大的黑人。
若是他们回到祖国,也同样面临这样的困境:每年一千万毕业生跟他们抢工作。而这一代海龟群体,他们无论在技能上、知识上、做事踏实程度上,并不比国内毕业生强多少。
所以,绕个圈回来,大多数还是会加入失业大军。当然,家境好的人,爹妈既然有能力让他出国留学,也会有能力帮他在国内抢到更好的工作。至于他们家境的优势能维持多久,那就得看时运了。
至于凤姐这样完全靠个人奋斗的底层人出国留学的人,大概不会回国了。
靠文凭改变命运,已经是上个时代的传奇故事。这是个需要靠独特思维创造自己人生的时代,你要发现自己的优势,把它发挥到极致。
只有主流观念的那些人,就会不断内卷,把自己一辈子耗进去。
关注备用号,日更发文不迷路。
失联三个月,随时可能再次失联,可添加下方微信号(请勿重复添加):
13 系列全部都有现货,欢迎下单:
原价 259的课程,如今紧急促销,只需要129 元,世界局势风云变幻,每个人都要了解的生存知识。
Setting up a Kubernetes cluster using Docker in Docker | Callista
Setting up a Kubernetes cluster using Docker in Docker | Callista ![]()

|
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på Twitter

In this blog post I will describe how to set up a local Kubernetes cluster for test purposes with a minimal memory usage and fast startup times, using Docker in Docker instead of traditional local virtual machines.
This blog post is part of the blog series - Trying out new features in Docker.
For a background on how Docker in Docker can help us to set up a local Kubernetes cluster, see the Background section in the blog post Setting up a Docker Swarm cluster using Docker in Docker.
This blog post is not an introduction to Kubernetes and the components that builds up a Kubernetes cluster. For an introduction of the concepts used in Kubernetes see: kubernetes.io/docs/concepts/.
We are going to use the GitHub project Mirantis/kubeadm-dind-cluster to set up a Kubernetes cluster using Docker in Docker and we will use Docker for Mac to act as the Docker Host for the Kubernetes nodes (running as containers in Docker for Mac).
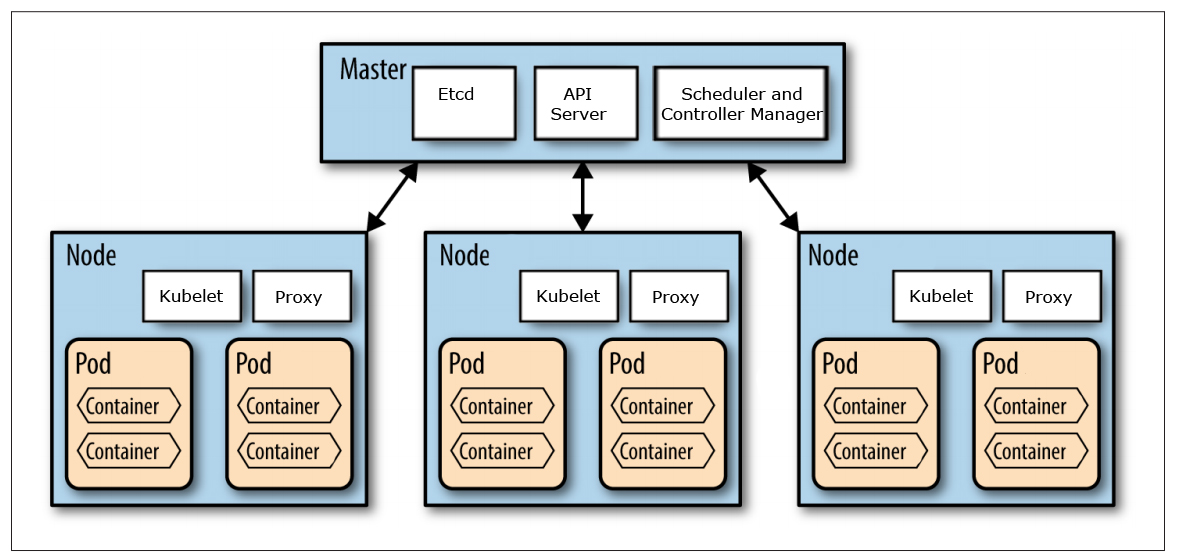
Source: http://nishadikirielle.blogspot.se/2016/02/kubernetes-at-first-glance.html
First, you need to have Docker for Mac installed, I’m on version 17.09.1-ce-mac42.
Next, you also need to have jq and md5sha1sum installed to be able to follow my instructions below. If you use Homebrew, they can be installed with:
brew install jq
brew install md5sha1sum Finally, clone the Git repo Mirantis/kubeadm-dind-cluster from GitHub and jump into the fixed folder:
git clone https://github.com/Mirantis/kubeadm-dind-cluster.git
cd kubeadm-dind-cluster/fixed We are good to go!
Start up a Kubernetes v1.8 cluster requesting 3 worker nodes in the cluster (default is 2):
NUM_NODES=3 ./dind-cluster-v1.8.sh up The first time the up command is executed it will take a few minutes and produce lot of output in the terminal window…
…in the end it should say something like:
NAME STATUS ROLES AGE VERSION
kube-master Ready master 2m v1.8.4
kube-node-1 Ready <none> 1m v1.8.4
kube-node-2 Ready <none> 1m v1.8.4
kube-node-3 Ready <none> 47s v1.8.4
* Access dashboard at: http://localhost:8080/ui Note: If you start up the cluster again later on, it will only take a minute.
Verify that you can see the master and worker nodes as ordinary containers in Docker for Mac:
docker ps It should report something like:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
766582a93d1f mirantis/kubeadm-dind-cluster:v1.8 "/sbin/dind_init s..." 9 hours ago Up 9 hours 8080/tcp kube-node-3
e1fc6bec1f23 mirantis/kubeadm-dind-cluster:v1.8 "/sbin/dind_init s..." 9 hours ago Up 9 hours 8080/tcp kube-node-2
b39509b9db77 mirantis/kubeadm-dind-cluster:v1.8 "/sbin/dind_init s..." 9 hours ago Up 9 hours 8080/tcp kube-node-1
a01be2512423 mirantis/kubeadm-dind-cluster:v1.8 "/sbin/dind_init s..." 9 hours ago Up 9 hours 127.0.0.1:8080->8080/tcp kube-master Ok, so let’s see if we actually have a Kubernetes cluster up and running:
kubectl get nodes It should result in a response like:
NAME STATUS AGE VERSION
kube-master Ready 2m v1.8.4
kube-node-1 Ready 55s v1.8.4
kube-node-2 Ready 1m v1.8.4
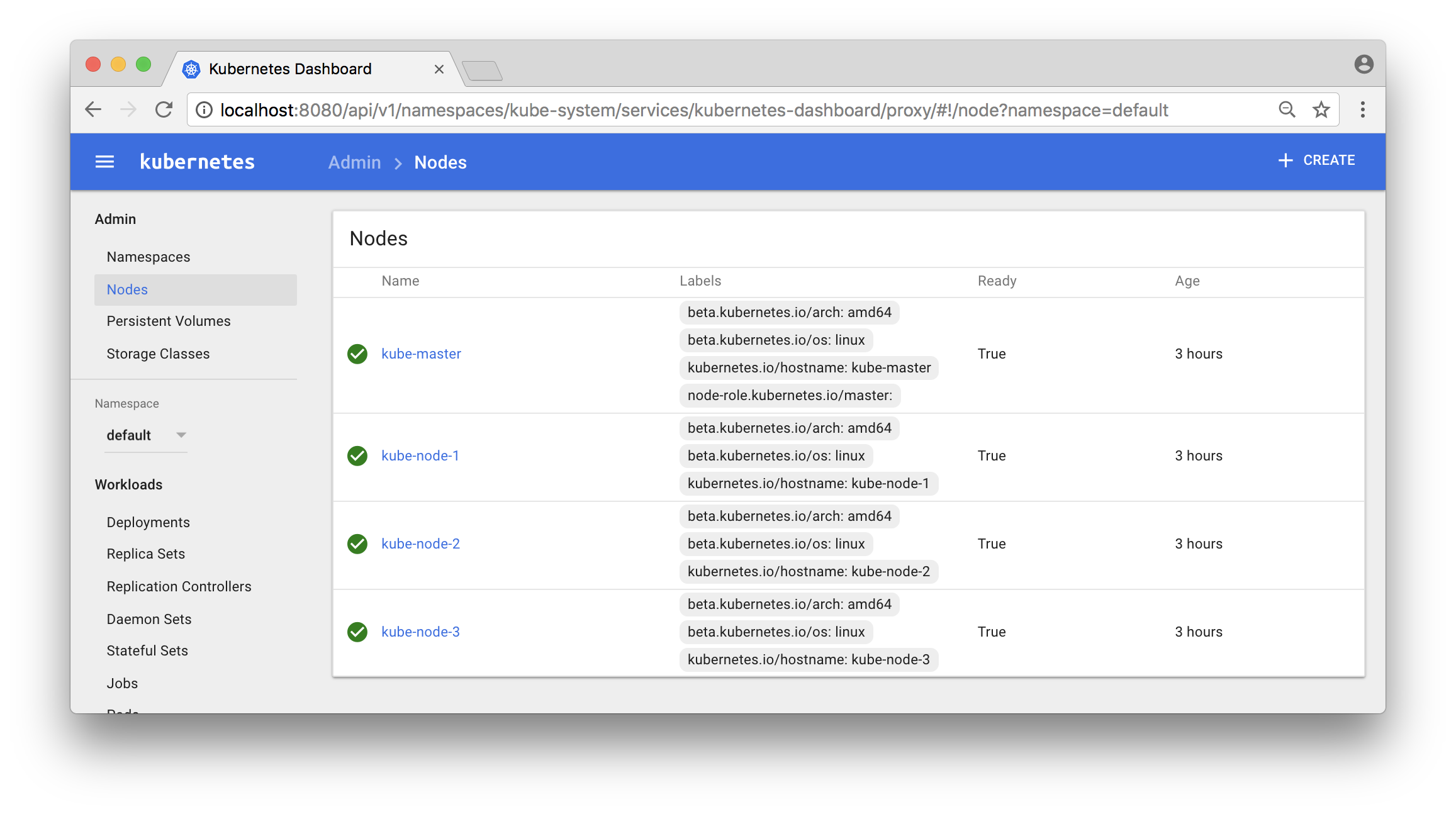
kube-node-3 Ready 1m v1.8.4 Also try out Kubernetes Dashboard at: localhost:8080/ui
Click on the “Nodes” - link in the menu to the left and you should see something like:
Now, let’s deploy a service and try it out!
I have a very simple Docker image magnuslarsson/quotes:go-22 (written in Go) that creates some random quotes about successful programming languages.
We will create a Deployment of this Docker Image and a Service that expose it on each node in the Kubernetes cluster using a dedicated port (31000). The creation of the Deployment object will automatically also create a Replica Set and a Pod.
Note: In more production like environment we should also set up an external load balancer, like HAProxy or NGINX in front of the Kubernetes cluster to be able to expose one single entry point to all services in the cluster. But that is out of scope for this blog post and left as an exercise for the interested reader :-)
First, switch to the default namespace:
kubectl config set-context $(kubectl config current-context) --namespace=default The default namespace should only contain one pre-created object, run the command:
kubectl get all It should report:
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kubernetes 10.96.0.1 <none> 443/TCP 5h Create a file named quotes.yml with the following command:
cat <<EOF > quotes.yml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: quotes
labels:
app: quotes-app
spec:
replicas: 1
selector:
matchLabels:
app: quotes-app
template:
metadata:
labels:
app: quotes-app
spec:
containers:
- name: quotes
image: magnuslarsson/quotes:go-22
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: quotes-service
spec:
type: NodePort
selector:
app: quotes-app
ports:
- port: 8080
targetPort: 8080
nodePort: 31000
EOF Create the Deployment and Service objects with the following command:
kubectl create -f quotes.yml Verify that we got the expected objects created, using the following command:
kubectl get all Expect output:
NAME READY STATUS RESTARTS AGE
po/quotes-77776b5bbc-5lll7 1/1 Running 0 45s
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kubernetes 10.96.0.1 <none> 443/TCP 5h
svc/quotes-service 10.105.185.117 <nodes> 8080:31000/TCP 45s
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/quotes 1 1 1 1 45s
NAME DESIRED CURRENT READY AGE
rs/quotes-77776b5bbc 1 1 1 45s Note: In the output above short names are used for object types:
po: Podsvc: Servicedeploy: Deploymentrs: Replica Set
We can now try it out using curl from one of the worker nodes:
docker exec kube-node-2 curl localhost:31000/api/quote -s -w "\n" | jq Output should look like:
{
"ipAddress": "quotes-77776b5bbc-5lll7/10.192.3.4",
"quote": "In Go, the code does exactly what it says on the page.",
"language": "EN"
} The most interesting part of the response from the service is actually the field ipAddress, that contains the hostname and ip address of the pod that served the request, quotes-77776b5bbc-5lll7/10.192.3.4 in the sample response above.
This can be used to verify that scaling of a service actually works. In the output from a scaled service we expect different values in the ipAddress - field from subsequent requests, indicating that the request is load balanced over the available pods.
Let’s try it out, shall we?
First, start a loop that use curl to sends one request per second to the quote-service and prints out the ipAddress - field from the response:
while true; do docker exec kube-node-2 curl localhost:31000/api/quote -s -w "\n" | jq -r .ipAddress; sleep 1; done Initially the output should return one and the same hostname and IP address, since we only have one pod running in the service:
quotes-77776b5bbc-5lll7/10.192.3.4
quotes-77776b5bbc-5lll7/10.192.3.4
quotes-77776b5bbc-5lll7/10.192.3.4
quotes-77776b5bbc-5lll7/10.192.3.4 Now, scale the quote-service by adding 8 new pods to it (9 in total):
kubectl scale --replicas=9 deployment/quotes Verify that you can see all 9 quote-service pods and also to what node they are deployed:
kubectl get pods -o wide Expected output:
NAME READY STATUS RESTARTS AGE IP NODE
quotes-77776b5bbc-42wgk 1/1 Running 0 1m 10.192.4.9 kube-node-3
quotes-77776b5bbc-c8mkf 1/1 Running 0 1m 10.192.3.8 kube-node-2
quotes-77776b5bbc-dnpm8 1/1 Running 0 25m 10.192.3.4 kube-node-2
quotes-77776b5bbc-gpk85 1/1 Running 0 1m 10.192.2.8 kube-node-1
quotes-77776b5bbc-qmspm 1/1 Running 0 1m 10.192.4.11 kube-node-3
quotes-77776b5bbc-qr27h 1/1 Running 0 1m 10.192.3.9 kube-node-2
quotes-77776b5bbc-txpcq 1/1 Running 0 1m 10.192.2.9 kube-node-1
quotes-77776b5bbc-wb2qt 1/1 Running 0 1m 10.192.4.10 kube-node-3
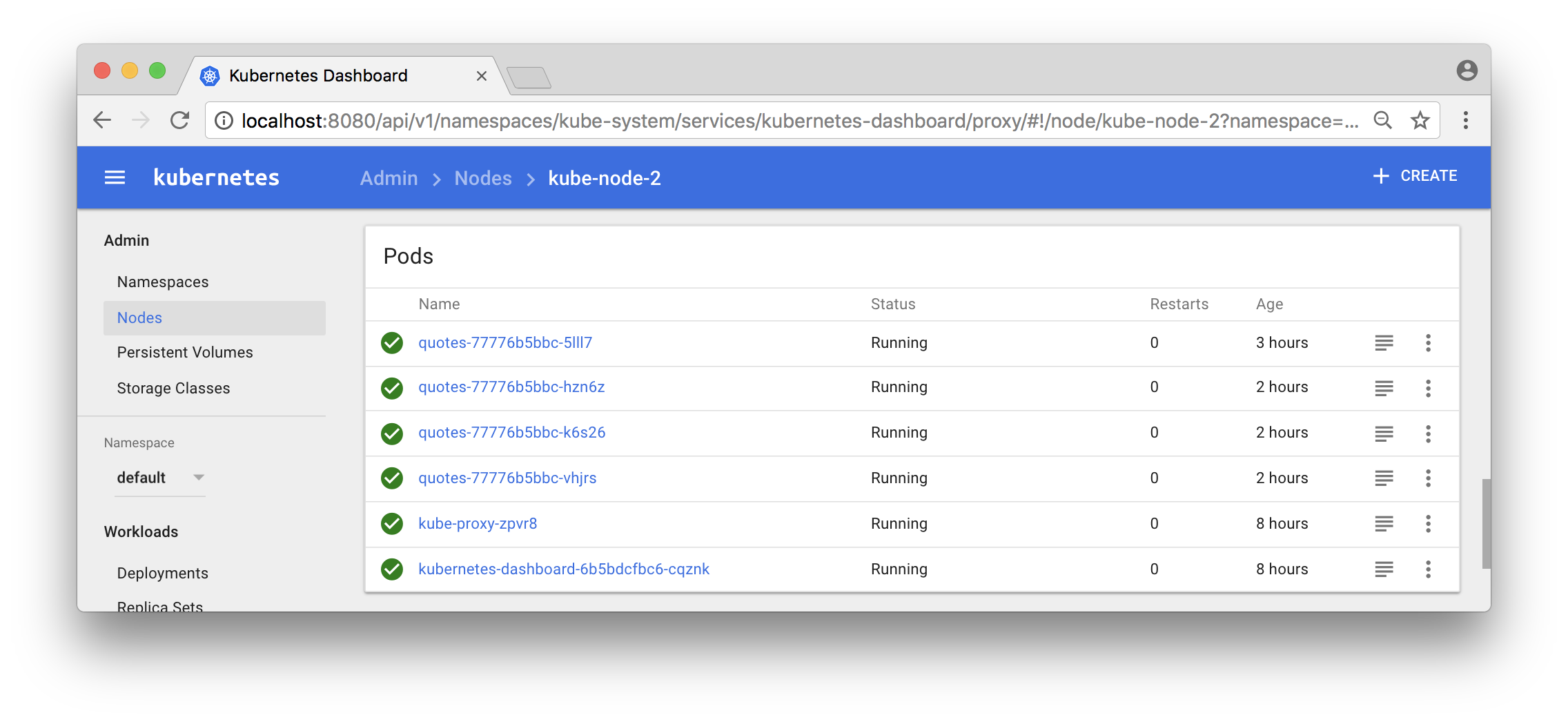
quotes-77776b5bbc-wzhzz 1/1 Running 0 1m 10.192.2.7 kube-node-1 Note: We got three pods per node, as expected!
You can also use the Dashboard to see what pods that run in a specific node:
Now, the output from the curl - loop should report different hostnames and ip addresses as the requests are load balanced over the 9 pods:
quotes-77776b5bbc-gpk85/10.192.2.8
quotes-77776b5bbc-42wgk/10.192.4.9
quotes-77776b5bbc-txpcq/10.192.2.9
quotes-77776b5bbc-txpcq/10.192.2.9
quotes-77776b5bbc-wb2qt/10.192.4.10
quotes-77776b5bbc-txpcq/10.192.2.9 Great, isn’t it?
Now, let’s expose the container orchestrator, i.e. Kubernetes, to some problems and see if it handles them as expected!
First, let’s shut down some arbitrary pods and see if the orchestrator detects it and start new ones!
Note: We will actually kill the container that runs within the pod, not the pod itself.
Start a long running command, using the --watch flag, that continuously reports changes in the state of the Deployment object:
kubectl get deployment quotes --watch Initially, it should report:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
quotes 9 9 9 9 1d Note: The command hangs, waiting for state changes to be reported
To keep things relatively simple, let’s kill all quote-services running on the first worker node:
CIDS=$(docker exec kube-node-1 docker ps --filter name=k8s_quotes_quotes -q)
docker exec kube-node-1 docker rm -f $CIDS The command should respond with the ids of the killed containers:
e780545ddd17
ddd260ba3f73
b4e07e736028 Now, go back to the “_deployment watch_” - command and see what output it produces!
It should be something like:
quotes 9 9 9 8 1d
quotes 9 9 9 7 1d
quotes 9 9 9 6 1d
quotes 9 9 9 7 1d
quotes 9 9 9 8 1d
quotes 9 9 9 9 1d The output shows how Kubernetes detected that it got short of available pods and compensated that by scheduling new containers for the affected pods.
Now, let’s make it even worse by removing a worker node, simulating that it is taken off line for maintenance work. Let’s mark kube-node-3 as no longer accepting either existing pods or scheduling of new pods:
kubectl drain kube-node-3 --ignore-daemonsets The command reports back what pods that was evicted from the node:
pod "quotes-77776b5bbc-jlwtb" evicted
pod "quotes-77776b5bbc-7d6gc" evicted
pod "quotes-77776b5bbc-cz8sp" evicted Kubernetes will however automatically detect this and start new ones on the remaining nodes:
kubectl get pods -o wide Reports back:
NAME READY STATUS RESTARTS AGE IP NODE
quotes-77776b5bbc-28r7w 1/1 Running 0 11s 10.192.2.10 kube-node-1
quotes-77776b5bbc-7hxd5 1/1 Running 0 11s 10.192.3.10 kube-node-2
quotes-77776b5bbc-c8mkf 1/1 Running 0 7m 10.192.3.8 kube-node-2
quotes-77776b5bbc-dnpm8 1/1 Running 0 31m 10.192.3.4 kube-node-2
quotes-77776b5bbc-gpk85 1/1 Running 0 7m 10.192.2.8 kube-node-1
quotes-77776b5bbc-grcqn 1/1 Running 0 11s 10.192.2.11 kube-node-1
quotes-77776b5bbc-qr27h 1/1 Running 0 7m 10.192.3.9 kube-node-2
quotes-77776b5bbc-txpcq 1/1 Running 0 7m 10.192.2.9 kube-node-1
quotes-77776b5bbc-wzhzz 1/1 Running 0 7m 10.192.2.7 kube-node-1 Note: The three pods with an age of 11 sec are the new ones.
We can also see that the node is reported to being unavailable for scheduling of pods:
kubectl get node Reports:
NAME STATUS AGE VERSION
kube-master Ready 1d v1.8.4
kube-node-1 Ready 1d v1.8.4
kube-node-2 Ready 1d v1.8.4
kube-node-3 Ready,SchedulingDisabled 1d v1.8.4 Great!
Let’s wrap up by making the node available again:
kubectl uncordon kube-node-3 The node is now reported to be back on line:
kubectl get node Results in:
NAME STATUS AGE VERSION
kube-master Ready 1d v1.8.4
kube-node-1 Ready 1d v1.8.4
kube-node-2 Ready 1d v1.8.4
kube-node-3 Ready 1d v1.8.4 But none of the existing pods are automatically rescheduled to the node:
kubectl get pods -o wide Still reports that all pods runs on node 1 and 2:
NAME READY STATUS RESTARTS AGE IP NODE
quotes-77776b5bbc-28r7w 1/1 Running 0 4m 10.192.2.10 kube-node-1
quotes-77776b5bbc-7hxd5 1/1 Running 0 4m 10.192.3.10 kube-node-2
quotes-77776b5bbc-c8mkf 1/1 Running 0 11m 10.192.3.8 kube-node-2
quotes-77776b5bbc-dnpm8 1/1 Running 0 36m 10.192.3.4 kube-node-2
quotes-77776b5bbc-gpk85 1/1 Running 0 11m 10.192.2.8 kube-node-1
quotes-77776b5bbc-grcqn 1/1 Running 0 4m 10.192.2.11 kube-node-1
quotes-77776b5bbc-qr27h 1/1 Running 0 11m 10.192.3.9 kube-node-2
quotes-77776b5bbc-txpcq 1/1 Running 0 11m 10.192.2.9 kube-node-1
quotes-77776b5bbc-wzhzz 1/1 Running 0 11m 10.192.2.7 kube-node-1 We can, however, manually rebalance our pods with the commands:
kubectl scale --replicas=6 deployment/quotes
kubectl scale --replicas=9 deployment/quotes Verify:
kubectl get pods -o wide Reports the expected three pod per node again:
NAME READY STATUS RESTARTS AGE IP NODE
quotes-77776b5bbc-2q26w 1/1 Running 0 1s 10.192.4.13 kube-node-3
quotes-77776b5bbc-bbhcb 1/1 Running 0 1s 10.192.4.14 kube-node-3
quotes-77776b5bbc-c8mkf 1/1 Running 0 13m 10.192.3.8 kube-node-2
quotes-77776b5bbc-dnpm8 1/1 Running 0 37m 10.192.3.4 kube-node-2
quotes-77776b5bbc-gpk85 1/1 Running 0 13m 10.192.2.8 kube-node-1
quotes-77776b5bbc-qr27h 1/1 Running 0 13m 10.192.3.9 kube-node-2
quotes-77776b5bbc-trrdh 1/1 Running 0 1s 10.192.4.12 kube-node-3
quotes-77776b5bbc-txpcq 1/1 Running 0 13m 10.192.2.9 kube-node-1
quotes-77776b5bbc-wzhzz 1/1 Running 0 13m 10.192.2.7 kube-node-1 That’s it, let’s remove the Kubernetes cluster:
./dind-cluster-v1.8.sh down If you start up the cluster again with the up command, it will start up much faster than the first time!
If you don’t want to start up the cluster again, at least in any near time, you can also clean up some data created for the cluster:
./dind-cluster-v1.8.sh clean If you start up the cluster again after a clean command you are back to the very long startup time.
For more blog posts on new features in Docker, see the blog series - Trying out new features in Docker.
Tack för att du läser Callistas blogg.
Hjälp oss att nå ut med information genom att dela nyheter och artiklar i ditt nätverk.
Drottninggatan 55
111 21 Stockholm
Tel: +46 8 21 21 42
Fabriksgatan 13
412 50 Göteborg
Tel: +46 31 20 19 18
© 2022 Callista Enterprise AB


![]()